Hi,
I really want to understand nanofactories and since convergent assembly is arguable one of the most important aspects of them I need to get I tight grasp on it. I already found out quite a bit and wrote it down here:
http://apm.bplaced.net/w/index.php?title=Convergent_assembly
But there still are some major things that I do not understand - partly or in full.
(*)Note: In the following when I'm going refer to "the main images of convergent assembly" I mean the four ones that can be found here:
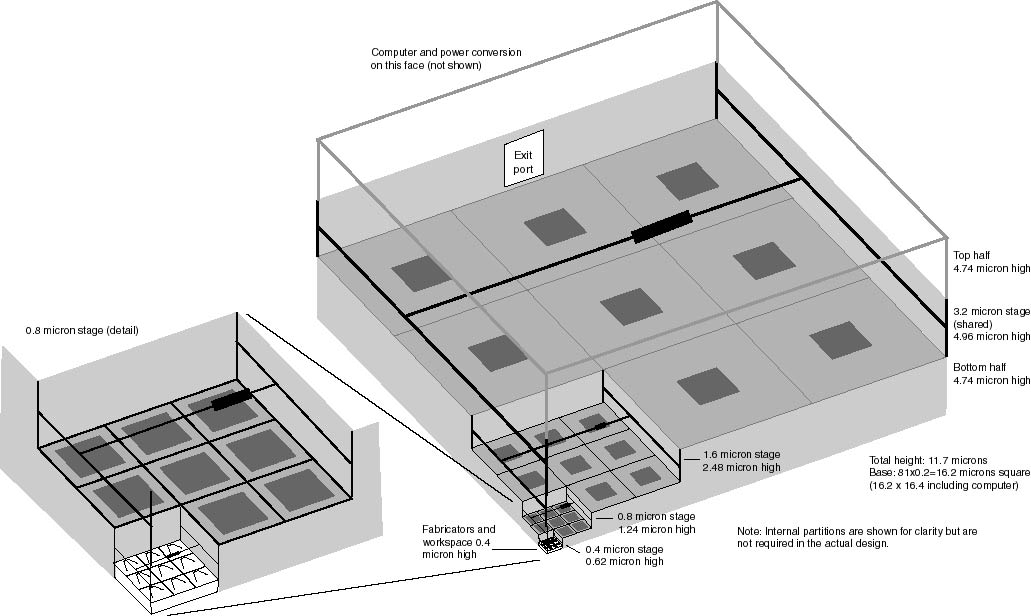
1) http://e-drexler.com/p/04/05/0609factoryImages.html
2,3,4) http://www.zyvex.com/nanotech/convergent.html
In case you're not aware: In these examples area branching and volume ratio steps are matching such that:
[ equal throughput on all stages <=> equal operating speeds on all stages ]
This seems reasonable for a first approximation.
In simple math:
Q2 = 1 s^3 f
Q1 = 4 (s/2)^3 2f = 1 s^3 f
=> Q2 = Q1 ![]()
s ... side-length
f ... frequency
Q2 ... throughput upper bigger layer (reference units)
Q1 ... throughput lower smaller layer
In main parameters (assuming constant speeds):
* area branching factor = 4
* volume upward ratio 1/(4x(1/2)^3) = 2
* scale-step = 2
!! please ask for details if that doesn't make sense to you !!
General questions about C.A.:
Question a)
Why do all the "main images of convergent assembly"(*) go all the way up with the convergent assembly steps to the size of the whole nanofactory. This changes the nanofactory from a convenient sheet format to a clunky box.
You can read here ...
http://apm.bplaced.net/w/index.php?title=Convergent_assembly
... why I think that "higher convergent assembly levels quickly loose their logistic importance"
What I wrote there too (for now under the headline "Further motivations" at the bottom) are some things that came to my mind about why the convergent assembly nevertheless goes up to the top in the main images of convergent assembly(*). These are:
* more simple construction of overhangs without the need for scaffolds (stalactite like structures)
* the automated management of bigger logical assembly-groups
* the simpler decomposition into big standard parts that can be put together again in completely different ways
* the possibility to keep everything in a vacuum till the final product release - this should not be necessary ***
(Can you think of any more?)
I don't deem any of them worthy enough though to sacrifice the nice sheet form factor that a nanofactory could have. It is clear that the bottom three convergent assembly steps (roughly: 1 mainly mechanosynthesis, 2 mainly radical surface zipping, 3 mainly shape locking) are absolutely necessary. But I'm not clear about the topmost convergent assembly stages -- they definitely do not increase the nanofactories speed so much is sure. (as reviewed above: cross sections at any hight have same throughput capacity)
*** Vacuum lockout is a special topic easily big enough to start separate thread.
late vacuum lockout: perfectly controlled environment <- one of Drexlers main points
not so late vacuum lockout: enforce recyclable shape locking micro-components (~1um?) such that we don't end up with APM being the greatest waste producer in human history (I question whether this will be avoidable). Consider this line out of the productive Nanosystems promo video: "the only waste product is clean water and warm air" ... and oops we forgot the product when it is no longer needed .... add too much silicon and you can't even burn it normally - you'd get flame inhibiting slack. (edit: Well, "Radical Abuncance" does mention recycling briefly but it treats it more like magical a black box.) Btw: I'm currently working on a simple and elegant vacuum lockout system for arbitrary shaped micro-scale-blocks -- but that's a seperate topic ...
Question b)
Why do all the "main images of convergent assembly"(*) use a low area branching factor of four (amounting to side-length branching of two). As the (in relation to nanofactories stupidly low-tech) current day 3D printers nicely demonstrate way bigger step-sizes can lead to practical production times. Let me formulate it like this: who would build an (advanced) robot to just put 8 parts together ?! Also usually stuff does not come apart in very vew equally sized parts.
Choosing a bigger step-size may be quite a bit slower than the absolute maximum possible (in case the bottom mill layers are pretty performant) but it has also two big advantages:
1) designers will have probably less to think about the production process
2) bigger steps make less steps - this is way easier to grasp for the human mind
To elaborate on point two: Suppose we choose a step-size in side-length of 32 ~= sqrt(1000) ... (instead of the common two -- 32 is still way lower than what todays 3D printers do) ... then we get from 1nm (5C atoms) to 1mm in only four steps where each step has a comprehensible size ratio.
like this: 1nm (1) 32nm (2) 1um (3) 32um (4) 1mm
(When designing in this setting it seems not so far fetched anymore to actually hit the limits and run out of space. You can actually realize for the first time there’s not infinite space at the bottom - so to say.)
Note that with bigger step-sizes the throughput balance stays perfectly in tact:
In simple math:
Q2 = 1 s^3 f
Q1 = 16 (s/4)^3 4f = 1 s^3 f
=> Q2 = Q1 ![]()
Main parameters:
* area branching factor = 16
* volume upward ratio = 1/(16*(1/4)^3) = 16
* scale-step = 4
Here is my supposition:
The reason why 32-fold size steps are usually not depicted is probably because you can barely see three levels of convergent assembly on a computer screen then. But there's a way around this! There is a possibility to map the layers of a nanofactory such that one can see all the details on all scales equally well. I made an info-graphic on this quite a while ago but it turns out the straight horizontal lines are actually wrong.
see here:
https://www.flickr.com/photos/…800/in/dateposted-public/
Recently I found Joackim Böttger's work which I think is rather relevant for the visualisation of convergent assembly configurations in nanofactories:
http://www.uni-konstanz.de/grk…ople/member/boettger.html
http://www.amazon.de/Complex-L…%C3%B6ttger/dp/3843901805
http://graphics.uni-konstanz.d…20Satellite%20Imagery.pdf
http://graphics.uni-konstanz.d…in%20Large%20Contexts.pdf
I wrote a python program do kind of such a such a mapping. Here's an early result:
https://www.flickr.com/photos/…363/in/dateposted-public/
I may try to apply it on some screen-shots of this video:
http://www.dailymotion.com/video/x4mv4t_zoom-into-hair_tech
I also have further plans with this which would be too much for here though.
Questions regarding uncommon forms of C.A.:
There are two exceptions I know of which deviate from the "main images of convergent assembly"(*):
I'll describe how I understand them below. If you spot some misunderstandings please point me to them.
exception a)
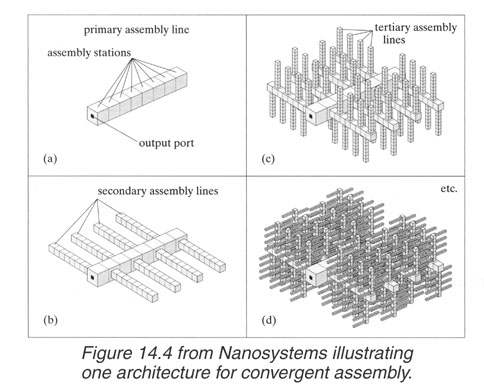
Nanosystems page 418 -- Figure 14.4.
Main parameters:
* area branching factor = 8
* volume upward ratio 1/(8x1/8) = 1
* scale-step = 2
Drexler himself writes (capitals by me):
"... This structure demonstrates that certain geometrical constraints can be met,
BUT DOES NOT REPRESENT A PROPOSED SYSTEM".
Here is how this looks like: http://www.zyvex.com/nanotech/images/DrexlerConverge.jpg
If I understand it right this is because in this arrangement the throughput capacity rises with a factor of two with every iteration downward creating a veritably massive bottleneck (30 iterations -> factor 2^30~10^9) at the top.
In simple math:
Q2 = [8s^3] f = 8 s^3 f
Q1 = 8[8(s/2)^3] 2f = 16 s^3 f
=> Q1 = 2*Q2 .... oops ![]()
exception b)
The convergent assembly in Chris Phoenix's nanofactory design that he describes here:
http://www.jetpress.org/volume13/ProdModBig.jpg
I am not talking about the geometrical design decisions but the main parameters of the chosen convergent assembly. In this regard it is completely identical to Drexlers (UNproposed) configuration in Nanosystem Figure 14.4. and that on ALL! stages since it has:
lower (stratified) stages: (chosen geometry not arbitrary scalable as Chris Phoenix points out himself)
* area branching factor = 3x3 (-1 redundant normally unused) = 8
* volume downward ratio (8x1/8)/1 = 1
* scale-step = 2
upper 3D fractal stages:
* area branching factor = 8 (+1 redundant normally unused)
* volume downward ratio (64x1/8)/8 = 1
* scale-step = 2
Major error here ??
Unless I am misunderstanding something I do spot a major error in reasoning here. The reasoning goes as follows: You want the throughput capacity of the very bottom stage upped to compensate for the slowness of this single stage of general purpose "fabricators".
BUT: deducing from this that continuing this approach further up the stages helps even more is actually incorrect. Doing this is actually detrimental. The reason: All further stages are super fast since they only have to assemble eight blocks to one 2x2x2 block thus this leads to the aforementioned upward tightening funnel in throughput capacity. While the stage right after the fabricators is seriously overpowered or equivalently under-challenged at some point up the stack the load starts to fit the capacity and from there on out the funnel takes effect. In spite of this exponential funnel situation the top stage still looks totally practical - which is nothing but amazing and once again proofs the insane potential of nanofactories.
What I think actually is necessary for a more throughput to throughput-capacity matched design is much much more parallelism in the bottom layer. When you stack those fabricators and thread by the finished parts fast some similarity to mill-style crops up here - which may not be too suprising.
(Such stacking may be necessary in one or two more stages - due to e.g. slow surface radical zipping - but that should be it -- that's as I understand the reason why the lowest three convergent-assembly-layer-stacks are actually becoming thinner going upward - as can be seen in the productive nanosystems video)
Imo in Chris Phoenix's nanofactory text separating the abstract convergent assembly details from concrete geometric implementation details and other stuff could have been done better. I may go through the trouble and crop out and cite the dispersed relevant pieces if requested.
What also bothers me is that although this is supposed to be a practical design it adheres rather closely to the very small side-length doubling steps which I've tried to argue against above.
As I've seen Chris Phoenix is member of this forum.
@Chris Phoenix:
If you happen to read this post I would be delighted to hear your thoughts about this.
Please check if you see any errors in my reasoning.
If not how you would modify your design?
Fine-tuning:
There are I think two main reasons to slightly deviate from the good first approximation of constant speed on all stages I've spoken of above.
Reason a)
At the bottom:
* limit in spacial mechanosynthesis density - manipulators are necessarily bigger than atoms
* limit in temporal density - slow down to prevent excessive friction heat since the big bearing surface area compensates even the big super-lubrication benefit
(these two are rather well known)
Reason b)
I have an idea which I call "infinitesimal bearings" - See here:
http://apm.bplaced.net/w/index…tle=Infinitesimal_bearing
This should allow us to cheat on the constant speed on all sizes rule especially in the mid sized area (0.1um .. 0.1mm).
Here's a maybe interesting observation:
To get a throughput capacity funnel that is widening in the upward direction (which will certainly be needed but has seemingly never been discussed) one needs a low area branching factor and a high volume upward ratio.
What would be the optimal geometry for this?
(____) widening -- (layered) constant-- (3D-fractal) tightening
This somewhat reminds me on space topologies: elliptical, plane, hyperbolic ....
Note any type can be forced in any geometric configuration for a few stages.
And finally to the biggest mystery of all I've encountered so far:
There's this discussion by J.Storrs Hall which I still need to chew through thoroughly.
Its about the scaling law for the replication time of proposed nanofactories.
It is actually mismatching the scaling law for replication observed in nature by an order of magnitude(?).
See here:
http://www.imm.org/publications/reports/rep041/
I think this is super relevant!
Some open questions regarding this:
easy: How would this look in a stratified configuration?
easy: How much is it "unscalable" in this configuration?
hard: How can the essence of this be visualized in a less abstract more intuitive way?
That is: Why does nature choose to do so?
....
---------------------------------------
ps: Please excuse for the size of this post but I wanted to have all the stuff of convergent assembly together to form a complete picture.
convergent assembly and its visualisation
-
-
I've now detangled the core convergent assembly decisions in Chris Phoenix's
"Design of a Primitive Nanofactory" document.
http://www.jetpress.org/volume13/Nanofactory.htm
I've separated it from other IMO less important decisions about geometric and other things.
Here are the relevant crop-outs:quote: Chris (CHRISPHOENIX)
4. Nanofactory Architecture
... The current design, ... uses only one block from each fabricator per product cycle. This implies that each stage will receive all its blocks in parallel. In general, then, each stage must have either eight (non-redundant) or nine or ten (redundant) inputs. (The first gathering stage has only four inputs, to compensate for the eighteen inputs of the final stage in the production module; see below.) ... A square of nine fabricators (one redundant) forms a stage. ... Likewise, a square of nine of these stages forms the next stage. This continues through several levels; in the current design, four levels is chosen ... unlike Merkle's design, each input port delivers only one block per product cycle instead of two. ...
4.3. Gathering stages
... product assembly requires 14 further assembly stages where each stage assembles 64 sub-blocks to produce eight product blocks. ... A final stage, ... assembles eight ... sub-blocks (per product cycle) to produce the final product. Note that the first stage in the Figure is not an assembly stage, but serves only to gather 8 sub-blocks for delivery to the next stage, since each production module makes only two blocks per product cycle. Each assembly stage gathers 64 sub-blocks from substages, assembles them within the assembly/delivery tube, and delivers the 8 assembled blocks to the superstage.
Since its a bit tricky to read out the specifics about the "welding" between the lower stages and upper stages with the frame of reference shifting around I'll reformulate it.
I hope I can make it more obvious that there is no discontinuity or convergent-assembly-character-change.
The four 4 lower stages (including the fabricators at the bottom) make up a production module which has 8(+1*) outputs
Now 2 production modules
with each 8(+1*)subblocks = 1fullblock of outputs
make 16(+2*)subblocks = 2fullblocks of output together.
This is a production module pair.
The first(isn't it the only one) gathering stage takes four production module pairs as inputs and thus gets 16*4=64subblocks which equates to 2*4=8fullblocks.
Those do not get assembled here yet. This does not change the character of the convergent assembly though. It makes just a small local delay.
Stages further up take 8*8=64fullblocks and assemble them to 8biggerfullblocks
(Did I get that right?)
As far as I can see all the these stages with identical convergent assembly characteristic can simply be added up. This makes all in all 4+14=16Stages.
Assuming a throughput capacity (not throughput!) of 1kg per second at the topmost stage (gross underestimation) calculating downwards toward the stage just before the fabricators leads to a throughput capacity of 2^16kg~=64000kg/second - wow. The fabricators at the bottom though won't come even close to 1kg per second of throughput. I see a major mismatch everywhere. I hope this formulation makes more clear what I'm trying to get at than the abstract formulation that I've given above.
I think it would be great to have a clean separation of convergent assembly parameters and geometric design.
This way one could just dial in the parameters (and step-sizes) and out comes an auto-generated 3D model.
Practical designs will probably only be viewable in their entirety (over wide scales) with visualization methods similar to the one I've outlined above.quote: Lukas (LSUESS)
What also bothers me is that although this is supposed to be a practical design it adheres rather closely to the very small side-length doubling steps which I've tried to argue against above.
Ooops I've missed that line:quote: Chris (CHRISPHOENIX)
The design can be compacted somewhat if multiple convergent assembly stages can be combined; such optimization is beyond the scope of this paper.
-
I found an interactive version of nonlinear mapping:
https://mrgris.com/projects/merc-extreme/
(Tip: turn on satellite view)What would be the most visually interesting while least politically, religiously, ideologically problematic place to focus at for a screenshot demonstrating that kind of the mapping?
This is already hard. Additionally asking for a place that can be easily identified by most of the worlds population is probably too much and likely leaves no results.
-
I found an interactive version of nonlinear mapping:
https://mrgris.com/projects/merc-extreme/
(Tip: turn on satellite view)What would be the most visually interesting while least politically, religiously, ideologically problematic place to focus at for a screenshot demonstrating that kind of the mapping?
This is already hard. Additionally asking for a place that can be easily identified by most of the worlds population is probably too much and likely leaves no results.
"Least problematic focus" appears to be a goal without a solid reason. If the audience is presumed to be that emotionally sensitive, exposure to non-linear mapping is probably an effort in futility. That said, something like the most ancient extant building might be sufficiently distant from present-day disputes that it could serve the desired purpose. One list of such entities: https://en.wikipedia.org/wiki/List_of_oldest_buildings
-
"Least problematic focus" appears to be a goal without a solid reason. If the audience is presumed to be that emotionally sensitive, exposure to non-linear mapping is probably an effort in futility.
True, for a such a super sensitive audience that's likely "small-minded" enough to confuse physical size with significance, exposure to non-linear mapping may lead to severe psychological breakdown (exaggerating joke of course).
I guess I have the problem of too many options and a lack of criteria for narrowing them down. Choosing the least problematic focus or better: avoiding the most problematic focus seemed to be a good starting point.
Old buildings are an interesting idea, I hadn't that one.
I guess the one most widely known of these is the "Great Pyramid of Giza" best viewed form the perspective of "Pyramid of Menkaure". https://mrgris.com/projects/me…b6b7dd3@29.97271,31.12854
A bit of an issue with these old buildings is that while they themselves are interesting around them usually is not very much interesting stuff present for a long stretch. This leaves a gap in the map. I had the idea of the European "North Kap" but that had the same problem there. Also these very old buildings usually are not imaged with super high resolution (unlike e.g. city centers) so they become blurry on the maximally magnified end of the map.I guess balancing interestingness on all size-scales is a good criterion.
This translates to looking for a kind of fractal succession. Maybe I should look here:
https://en.wikipedia.org/wiki/…inuously_inhabited_cities
since fractal coastlines (not referring to fractal dimension here as usually done) seem to have been a catalyst for "early" seafaring civilization.Maybe: Greece Athens "Sunken Lake" (with caves unexplored to this day).
https://en.wikipedia.org/wiki/Vouliagmeni#Lake_Vouliagmeni
Viewing coordinates: 37.807075,23.786131
https://mrgris.com/projects/me…b6b7dd3@37.80707,23.78613This place near my home: 48.132664,16.392811 has kind of a fractal situation going on.
https://mrgris.com/projects/me…b6b7dd3@48.13266,16.39281
(btw: the Alps make a nice bow in this view)
I could motivate using a place in my hometown Vienna by arguing that Erwin Schrödinger was born there.
But actually I don't want to focus on specific people.
There's a (rather un-pretty) place named: "Schrödingerplatz"
Viewing coordinates: 48.241081,16.437511 or 48.240963,16.437373
https://mrgris.com/projects/me…b6b7dd3@48.24108,16.43751
The perspective with that center lines up Vienna's four water-ways nicely.Two further ideas I came up by using the topic of APM/MNT as a rough guideline criterion:
The "Swarovski Kristallwelten" exposition in Austria Wattens:
https://en.wikipedia.org/wiki/…allwelten_(Crystal_Worlds)
Viewing coordinates: 47.294340,11.600365
https://mrgris.com/projects/me…b6b7dd3@47.29434,11.60036
Topical focus is actually rhinestone though not gemstone.The "Atomium" in Belgium Brussel:
https://en.wikipedia.org/wiki/Atomium
Viewing coordinates (from south-west): 50.894463,4.340803
https://mrgris.com/projects/me…0b6b7dd3@50.89446,4.34080
(This perspective from south west is best since it shows all continents and no building shadows)
The topical focus is actually nuclear technology though.
The surrounding landscape is rather flat, wheat field paved and bland.
Wikipedia (en) says: Distributing pictures of the Atomium is only legal since last year. What?! -
I guess the one most widely known of these is the "Great Pyramid of Giza" best viewed form the perspective of "Pyramid of Menkaure". mrgris.com/projects/merc-extreme/#0b6b7dd3@29.97271,31.12854
A good choice - Giza was the first place I thought of when I started thinking of well known but temporally distant things. But as you note, not much interesting in its vicinity.
Maybe: Greece Athens "Sunken Lake" (with caves unexplored to this day).
en.wikipedia.org/wiki/Vouliagmeni#Lake_Vouliagmeni
Viewing coordinates: 37.807075,23.786131
mrgris.com/projects/merc-extreme/#0b6b7dd3@37.80707,23.78613Looks interesting because it encompasses an area rather than a small object. But it is probably obscure enough to need a brief introduction (though any choice would need one.)
Alles anzeigenThe "Atomium" in Belgium Brussel:
en.wikipedia.org/wiki/Atomium
Viewing coordinates (from south-west): 50.894463,4.340803
mrgris.com/projects/merc-extreme/#0b6b7dd3@50.89446,4.34080
(This perspective from south west is best since it shows all continents and no building shadows)
The topical focus is actually nuclear technology though.
The surrounding landscape is rather flat, wheat field paved and bland.
Wikipedia (en) says: Distributing pictures of the Atomium is only legal since last year. What?!I like this choice. The art is sufficiently arresting to the eye, though, that it might distract from the surrounding view which highlights the non-linear mapping. The copyright aspect is Interesting. Belgium's "freedom of panorama" copyright laws are new to me - U.S. copyright law is different. (It occurs to me that Google satellite maps must incorporate millions of copyright violations caused by photos of public buildings in countries whose laws don't allow publication of them without permission, which I doubt Google got.)
{kind=link}
Jetzt mitmachen!
Sie haben noch kein Benutzerkonto auf unserer Seite? Registrieren Sie sich kostenlos und nehmen Sie an unserer Community teil!