I wanted to have the results of the paper:
– [FiMM] Evaluating the Friction of Rotary Joints in Molecular Machines
and the numbers in:
– [N] Nanosystems: Molecular Machinery, Manufacturing, and Computation
in a comparable form (motivation further down).
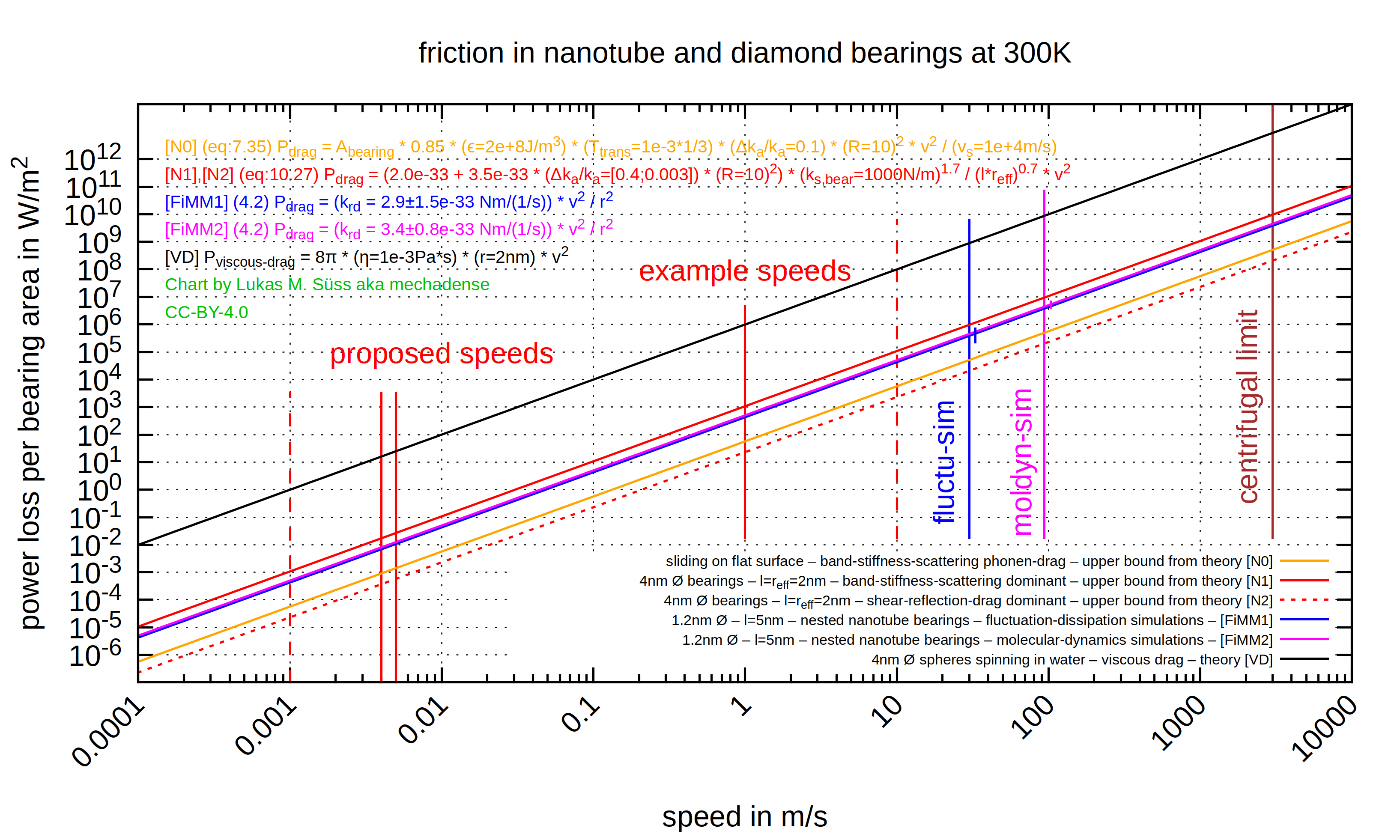
So I converted what I found to common units and combined them together into a single plot.
I got some surprising results:
Simulation results in [FiMM] exceeding conservative upper bounds in [N]?
Estimations in Nanosystems [N] are supposed to be highly reliable upper bounds,
so somewhat accurate simulations delivering values above (or only slightly below)
the Nanosystems values are a sign for some potential error.
The two mutually quite consistent nanotube simulations from [FiMM] are
both quite far (~10x) above Nanosystems upper bound for the flat-surface-case of equal area.
It could be that flat surface friction is higher than for very small diameter bearings.
But that much and more? I doubt it.
(I maybe need to check out the limit for big diameter bearings)
The upper bound for the diamond bearing case is (as it should be) above the simulations.
But only by a for Nanosystems quite small margin of very crudely 3x.
Have I made some error?
Or is there a genuine issue?
A review would be appreciated.
Regarding the lowest friction dashed red line:
Nanosystems mentions a special trick that could be used to lower friction by a further whopping 1000x.
(dropping band-stiffness-scattering drag below irreducible remaining shear-reflection-drag – via proper bearing design)
This one is way below the friction levels in [FiMM] but that's ok since the simulated nanotube bearing does not apply this trick.
I'm not entirely sure whether I comprehend that trick correctly.
It is not visually illustrated in Nanosystems.
More on that later.
Suprisingly high levels of friction for the name "superlubricity"
As just one random example picked form the chart there is about 100W/m^2 at 1m/s.
Compared to what is possible with macroscale ball bearings that's not small. I wasn't really expecting that.
Guess "superlubricity" really refers more to the complete absence of static friction
rather than to small dynamic friction.
Wikipedia page seems not aware of that:
https://en.wikipedia.org/wiki/Superlubricity
What's up here?!
Luckily the scaling law "smaller machinery features higher throughput per volume" saves the day.
In so far as it allow to do plenty of the obvious solution:
Going down to lower speeds since "halving speed quarters friction"
(and distributing speed differences over several stacked interfaced).
The up to 1000x lower friction trick:
Nanosystems page 174 bottom (7.3.5.c.):
"As discussed in chapter 10, Δk_a/k_a can be made small in bearings of certain classes, …"
Nanosystems page 292 (10.4.6.c.):
"… For first-row atoms (taking carbon as a model), Δk_a/k_a ≈ 0.3 to 0.4 (at a stiffness-per-atom of 1 and 10 N/m respectively)
where d_a = 0.25 nm, and ~0.001 to 0.003 where d_a = 0.125nm. This value of d_a cannot be physically achieved in coplanar rings, but it correctly modeles a ring sandwiched between two other equidistant rings having d_a = 0.25nm and a rotational offset of 0.125nm."
Given Figure 10.9. (page 285 before) I think "coplanar rings" here actually refers to "cocylindrical rings".
– d_a is the (possibly virtual) interatomic spacing along the bearings circumference
– k_a is the stiffness-per-unit-area of the bering interface
– Δk_a is the peak-to-peak variation of this stiffness due to "alignment bands" (spacial corrugation interference periods)
I totally don't understand how only halving the
(virtual) inter-atomic spacing can make the friction drop by almost a 1000x ?
That is: How halving d_a makes Δk_a/k_a go down by a factor of 1000x.
Anyone any idea?
Also I wonder if this would work with the offset being applied to atoms that are situated
further axially along on the same surface if they are (sideways) coupled stiffly enough (like alternating rows).
That option would remove the hassle of needing to design radially wedged bearings.
Anyone knows?
Motivation:
Showing how the scaling law for throughput is the main factor driving friction losses down.
And creating awareness about this scaling laws unoverstatable importance.
I eventually want halfway reasonable friction-loss-numbers for
an animation visualizing the (IMO much too unknown) scaling law of
"higher throughputdensity of smaller machinery"
Preliminary state here:
– YouTube+APM again
There was an article on Erics former website featuring this scaling law, but
I can't even find it on the Internet Archive anymore.
So I started making this animated 3D-model.
Further plans for making charts that are relevant for nanoengineering:
I'd like to eventually get to a chart that takes into account desirable deliberate deviation from keeping absolute speeds constant over scales.
A chart where halving speed comes with a doubling of area (and proportional productive machinery volume) such that overall throughput stays the same.
This leads to:
– many parallel lines each for a specific total throughput.
– linear rather than quadratic lines (half the slope in double-log chart)
– absolute power loss on the y-axis ~> getting back to powerloss-per-area is seriously confusing I found
There are a lot of details so I leave that for an eventual later post.
Transport dissipation losses in soft nanosystems:
Viscous drag being so much higher is expectable.
[VD] https://web.archive.org/web/20…om/p/04/03/0322drags.html
But this does not show inferiority of soft nanosystems in terms of efficiency, as I've initially wrongly assumed.
What one would want to compare here is diffusion transport.
But the speed of diffusion transport being distance dependent makes it difficult to compare.
For a desired diffusion speed this would I presume need assumptions on
– spacial pit-stop-membrane crossing frequency
– energy dissipation per pit-stop
– size of transported particles
Maybe something to look into …
Attached:
My preliminary version of the compiled friction results chart.
I may eventually publish the gnuplot source to github.